
In Big Data technology, the Spark application is a self-contained distributed data processing engine. It runs the user code to derive the result. It runs like any other independent programs. A spark application is used for a single batch job. Generally, the Spark application is capable of running various processes on its behalf even when it is not running any job.
Hence, large scale data processing and real-time analytics are precious offers from the Apache Spark application. It also helps in scaling business intelligence using different types of libraries and functions. There are many organizations that are using Spark application analytics services for their high-end business activities. This platform provides smart solutions for businesses with effective data analysis and other services too.
Apart from the DAG performance engine, the Spark app is more user-friendly. These applications can be written in different programming languages like Java, Scala, Python. It also supports these languages mainly. Moreover, it also involves many Machine Learning libraries that help in building high-performance apps.
By implementing the Spark application many business organizations are getting benefits across the globe. The large scale businesses that are using the Spark application are Amazon, Yahoo!, eBay, Alibaba, etc.
While implementing the Spark application, it involves many runtime concepts such as driver, executor, task, job, stage, etc. These concepts of knowledge are important to draw fast and efficient Spark programs.
Spark Application manager
The application manager is responsible for managing all applications across the nodes. To understand the Spark application implement process, we need to know some concepts.
The major components of the Spark app include the following;-
- Driver
- Master
- Cluster Manager
- Executor
All these components generally run on the worker nodes. The Spark application lifecycle begins with the Spark Driver and also finishes with the same. It's a kind of process that submits applications to the Spark platform. In the further process, the implementation involves SparkSession, application planning, and its orchestration, and other functions.
The Spark executors are the processes within this platform where DAG tasks run. A worker node that hosts executor processes usually has a fixed number of executors allotted. Similarly, the Spark cluster manager and the master are the two different processes that observe, store, and distribute the allocated cluster resources where the executors usually run.
There are some other concepts that further comes in the way to know about the Spark app and its implementation. Just have a look at these contexts in detail.
The Spark context
This Spark context is the entry point for any Spark application which is needed in every Spark program. In this, the Spark shell uses to create this context for the users. Here, the Spark program needs to create a SparkContext object that informs the Spark to access a cluster by way of the resource manager. As the Spark shell already created a Spark context. The user can terminate the Spark program using an sc.stop call.
The Spark application consists of two main processes such as the Driver process and the executor process. Here, the executor process runs the main function which is included in the node of a cluster. The driver process includes three main things. These are maintenance of Spark application information, giving responses to users program, analyzing, distributing across executors, etc. Moreover, the driver process is an important part of the Spark application which maintains all the information of the application throughout the lifetime.
The executors are responsible for executing code and reporting the computation state and back to the driver node after completion.
To get practical experience in using the Spark application, Big Data Online Course will help much more.
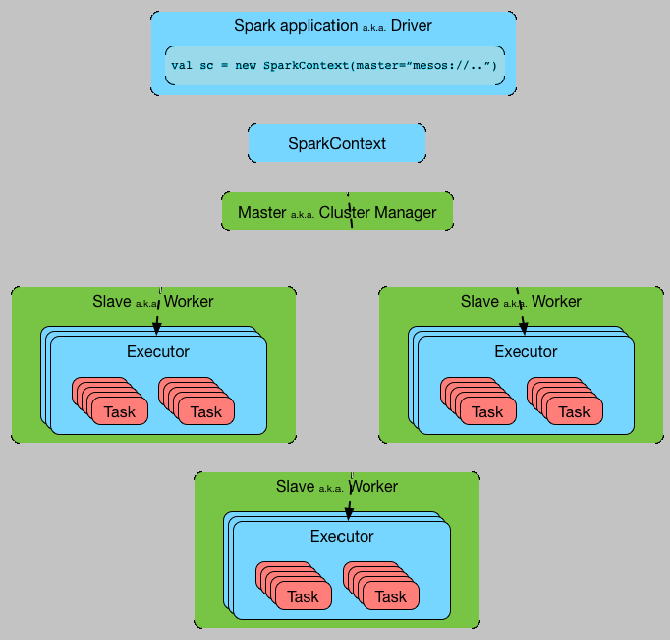
Spark Application cluster
The Spark application can run locally using different worker threads and without the use of any distributed processing upon cluster. Here the local mode of a cluster is very useful for the development and testing of applications. Moreover, the cluster is most preferable for production also.
Cluster Resource Managers
Three different resource managers support a cluster of Spark applications. They are Spark Standalone, Hadoop YARN, and Apache Mesos.
Spark consists of a Spark Standalone which is limited in configuration and scalability. Moreover, it is easy to install and run and also useful for development and testing. Further, there is no security and support for this resource manager.
The Hadoop YARN exists within CDH (Cloud Distribution Hadoop) and is useful for production sites. Moreover, it allows users to share cluster resources with other applications also.
Apache Mesos was a popular platform that supports Spark. But in the present, it is not that much useful as other resource managers.
Running the Spark on Hadoop YARN
At this stage, the Spark application is tested by running on Hadoop YARN. In this context, it runs on client mode. Here, the resource manager opens the main application master which opens the executor to execute the program. Moreover, when the executor finishes the processing of the application then it returns the results to SparkContext. Similarly, another client mode opens the SparkContext and runs the same process. Here, the process passes through several client modes.
Like the above process, the SparkContext also runs and tests through Cluster-mode also. Thus, it proves that the Spark application runs in different modes.
Running Spark Application Locally
To run the Spark application locally, the user has to use the spark-submit-master. Here, it offers various options to run the Spark locally where it uses many threads while it’s running.
Similarly, to run the application on a cluster, there also different cluster options such as Yarn-client, Yarn-cluster, etc.
||{"title":"Master in Big Data", "subTitle":"Big Data Certification Training by ITGURU's", "btnTitle":"View Details","url":"https://onlineitguru.com/big-data-hadoop-training.html","boxType":"demo","videoId":"UCTQZKLlixE"}||
Dynamic Allocation in Spark
Here, the Dynamic allocation allows the Spark application to add or remove the executors where it can dynamically allocate the executors as well. The Dynamic allocation within Hadoop Yarn enables at the site level instead of the application level. Moreover, this allocation is disabled for a single or individual application.
Finally, here we need to configure the Spark app. Spark provides several properties for the configuration of a Spark Application. These include spark. master, spark.local.dir, spark.executor.memory and spark.driver.memory. Moreover, the Spark applications configured by declarative or programmatic methods.
The above process explains the implementation of the Spark application in different steps.
Use of Spark Application
Today Spark is used widely among different industries for different purposes. This application has many uses and benefits. Here, we look into some prominent uses of Spark applications in different sectors.
Event Detection: The features of the Spark apps allow various entities to track the behaviors of system protection. Various institutions like finance, health; etc use these triggers to detect potential threats. This will help the organizations to protect themselves and customer values from potential frauds.
Machine Learning: The Spark application combines with scalable Machine Learning libraries to perform advanced analytics. Such as classification, clustering, predictive analysis, customer segmentation, etc. Furthermore, this makes Spark to become more intelligent among various technologies.
Interactive analysis: Among many features of Spark there is another special that supports interactive analysis. The Spark applications using Apache make the processes much faster as it doesn’t process queries by doing a sampling test. Moreover, companies like Uber, Pinterest, etc also use this platform for their smooth operations.
Moreover, the use of Spark apps in the banking sector is much useful. Today most banks use Spark to analyze social media profiles, calls, complaints, logs, emails, etc. This helps to provide a better customer experience. It is useful to cross-check the customer payments where they happen at an alarming rate from different locations. Furthermore, it helps to detect various financial frauds relating to transactions. The banking entities use analytics to identify different patterns around the happenings of transactions and other financial activities. Moreover, the banks follow many security measures but due to various illegal activities, they may be broken. Here, the Spark uses intelligence to detect such kind of activities to find out risks.
||{"title":"Master in Big Data", "subTitle":"Big Data Certification Training by ITGURU's", "btnTitle":"View Details","url":"https://onlineitguru.com/big-data-hadoop-training.html","boxType":"reg"}||
E-commerce use
Some e-commerce giants such as Alibaba, eBay, use this application to analyze data that generates enormously. Every day we see that a lot of transactions are done by several customers. This helps to improve the targeted customers well with their services. Moreover, the companies provide customer support well to retain their customers and also offer attractive discounts. Spark app helps to identify such customers and prioritizes them for the organization.
Further, there are other industries that also use this application like Healthcare, media, and entertainment, etc. Media companies like Netflix, Pinterest, etc, use this platform to provide a better recommendation to their customers. This recommends the latest events, podcasts, etc where real-time streaming is possible.
Use of Spark application in data analytics
Today data scientists also thinking about how the Spark application is beneficial for businesses. Further, the Spark app is advanced than the usual analytics software that makes it easy for users and data access. Let us discuss a few uses of this application in data analytics.
Analytics made easier
Many companies are using basic analytics for their daily operations. But if you want to make some difference in the view of your business data, then you can try the investment in advanced analytics. This helps in leveraging data for the organization. Among these, Apache Spark is the platform that provides various tools and libraries that are capable of performing advanced analytics.
Easy integration solution
Organizations usually use the Hadoop platform for data storage and process. Hence, by integrating the Spark app with this, users can access various data from Hadoop without any disruption. Here, it doesn’t need any additional storage or power consumption. Moreover, integrating the Spark app with Apache Hadoop and other platforms makes it easier, simple, and efficient for analysis.
Easy usage
Making use of the Apache Spark app for data analysis is the best choice for the employees within any organization. This is very easier to handle platform for the new people for their needs. Moreover, Apache Spark offers easy to use tools and understandable analytics. For people who want to try advanced analytics for their easier work, this platform could be the best one.
Flexible
Apache Spark application is more flexible for all the aspects, to use over any device or operating system. With the combination of other platforms, it works much easier along with supporting other programming languages. The APIs of Spark application include Python, R, Scala, Java, etc.
Data processing
With this application integration, users can access data and process it across different platforms. Whether they are sources, applications, or devices. This platform helps in automating the data process that streamlines your data apps without human involvement.
Real-time data analysis
The implementation of this application provides users with real-time analytics of data collected from different sources. There are many data types that are available but they lapse identity with the passing of time. Thus, real-time and up-to-date data is necessary to make any predictions and informed decisions. It helps in running agile analysis of data with all aspects that are in need.
Conclusion
Thus, the above writing explains how to implement a Spark Application and its various uses in different fields. Its application to the different fields helps to analyze, detect, and preserve precious data and information. This makes it popular among Big Data applications. Using Spark, many companies are performing well along with the latest updates. It provides real-time engagements with user data and organizations.
To get more knowledge of this application one can opt for Big Data Online Training from online resources. This learning may help to enhance skills and career growth in this field.